
本報訊
多年來,網站透過robots.txt檔案列出網頁爬蟲不被允許存取該網站的資訊。圖像軟件巨頭Adobe希望為圖像建立類似標準,為圖像的「內容憑證」增添一項工具,讓創作者對哪些內容可被用於訓練AI模型有更多控制權。
內容憑證(content credentials)納入圖像檔案的元數據,用於識別真實性和所有權的資訊,由多家互聯網及科企參與的內容真實性標準組織「內容出處與真實性聯盟」(C2PA)致力達成。
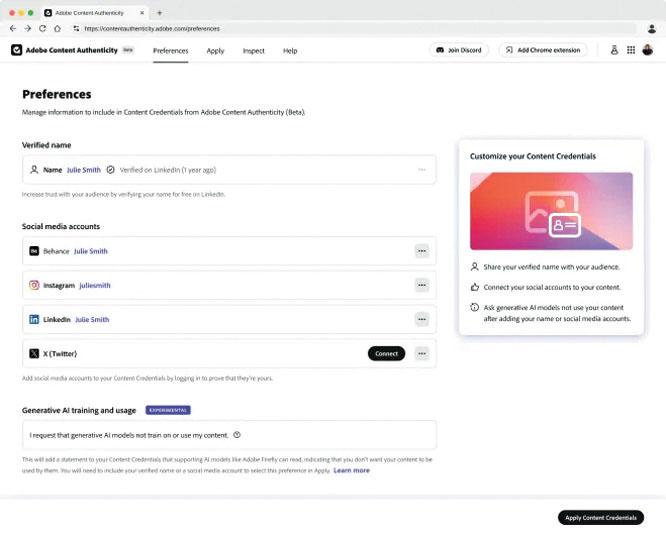
Adobe推出一款網頁工具「Adobe內容真實性程式」(Adobe Content Authenticity App),讓創作者將內容憑證附加到所有圖像文件,即使這些圖像不是透過Adobe自家工具創作或編輯。還讓用戶勾選一個方塊,表明他們的圖像不應用於模型訓練。
這款網頁程式讓用戶附加其內容憑證,包括名字和社交媒體帳號等,可以一次將這些憑證附加到最多50個JPG或PNG檔案。Adobe還與微軟旗下社群網絡領英(LinkedIn)合作,利用對方的驗證程序,有助證明為圖像附加憑證的人在領英擁有帳號。用戶也可將自己的社交平台Instagram或X帳號附加到圖像內,但與這些平台的驗證並無整合。
Adobe尚未與任何AI模型公司達成協議採用這項標準。Adobe同時發布一個谷歌瀏覽器Chrome的擴充程序,供用戶來辨別圖像「內容憑證」。
Adobe稱,內容憑證程式結合使用數位指紋、開源浮水印和加密元數據,將元數據嵌入圖像的各個像素中,因此即使圖像被修改,元數據也保持不變。這意味著用戶可以使用Chrome擴充功能檢查Instagram等本身不支援該標準的平台上的內容憑證。如果使用者在圖像上附加了內容憑證,他們就會在圖像上看到一個小的「CR」符號。









